K-近邻算法:如果一个样本在特征空间中的K个最相似的样本中的大多数属于某一类,则该样本也属于这个类别。
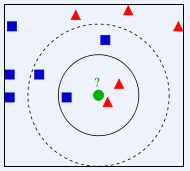
如图,有两类不同的样本数据,蓝色的小正方形和红色的小三角形,绿色的圆是待分类的数据。
·如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类
·如果K=5,绿色圆点的最近的5个邻居是2个红色小三角形和3个蓝色小正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类
三个基本要素:
·K值的选择
·距离度量:距离度量一般采用Lp距离,当p=2时,即为欧氏距离,在度量之前,应该将每个属性的值规范化(不同的样本基于不同的权重),这样有助于防止具有较大初始值域的属性比具有较小初始值域的属性的权重过大.
·分类决策规则:由输入实例的K个最临近的训练实例中的多数类决定输入实例的类别
KNN算法本身简单有效,它是一种 lazy-learning 算法,分类器不需要使用训练集进行训练,训练时间复杂度为0。KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为n,那么KNN的分类时间复杂度为O(n)。
数据库样例:CIFAR-10
在进行K-近邻算法训练时我们可以使用数据库样例来进行训练。
CIFAR-10数据集包括10个类,共有60000张32x32的图片,每个类有6000张图像。这里有50000张训练图像和10000张测试图像。数据集分为五个训练批次和一个测试批次,每个具有10000张图像。
曼哈顿距离
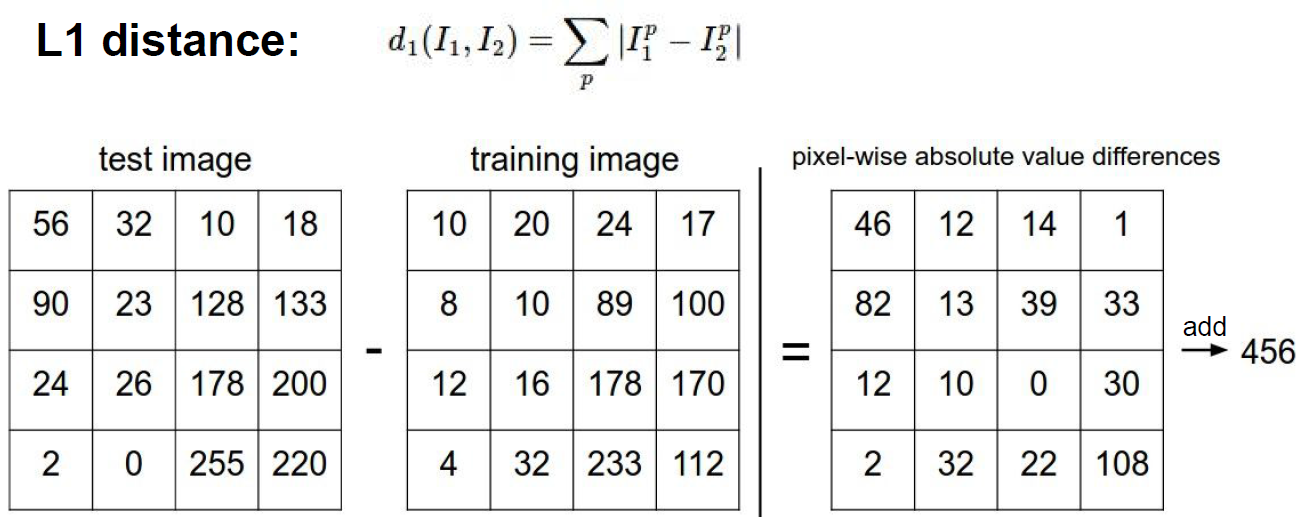
比较对应像素点上的差异,然后把差值累加在一起作为测试图像与训练图像之间的距离。
每张图片与测试集中图片比较,找出与其L1距离最小的样本的标签,作为它的标签
欧几里得距离

超参数:对于最终的结果有很大的影响的参数
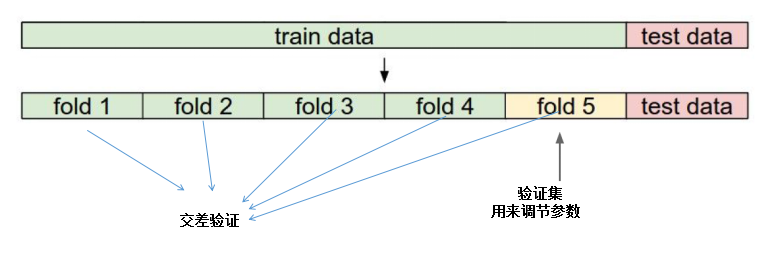
超参数的选择:
错误的做法:多次用测试数据实验,找到最好的一组参数组合。(测试数据只能最终用)
正确的做法:测试的数据还是测试的数据,把训练的数据切分成5份,前4份用来训练,后一份用来做验证集,在验证集上尝试不同的超参数,最后保留表现最后的那个。前5份交叉验证,能够帮助我们在选取最优超参数的时候减少噪音。一旦找到最优的超参数,就让算法以改参数在测试集跑且只跑一次,并根据测试结果评价算法。
背景主导
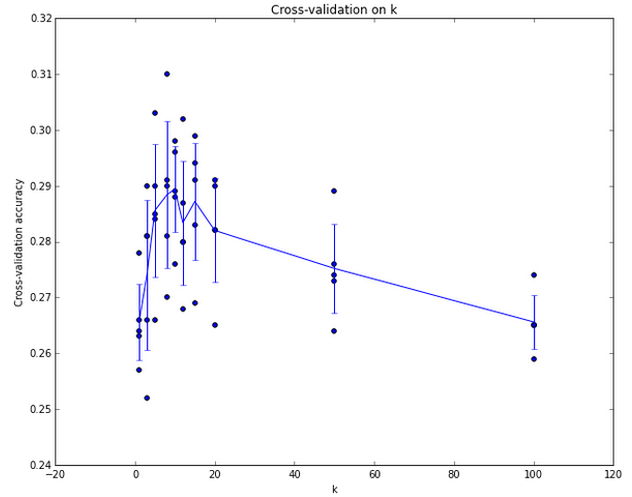
看图,是K近邻算法在图像分类上不同K值的精准度。可以看出K近邻算法在图像分类中并不理想,这是为什么呢?因为K近邻算法计算的是图片上的每一点像素,这就很容易造成背景主导,因此我们在图片分类中不使用这种算法。

下图是原图和其经过不同变换的图片,它们之间具有相同的L2距离,但是差别却非常大,因此K近邻算法在图像分类中是从来不用的。

